ベイズの定理から見るガン検査
November 12, 2013 at 03:01 AM | categories: statistics |http://www.huffingtonpost.jp/2013/11/10/cancer-test_n_4252707.html
高校生がすい臓がん発見の画期的方法を開発したという記事が話題になってます。
この検査法の改善が統計的にどういう意味をもつのか実際にベイズの定理をつかって計算してみます。
ここでは以下のような問題を考えることとします。
あるガン検査法は、被験者ががんの場合はp1の確率で陽性になり、被験者ががんでなければp2の確率で陰性になります。被験者ががん患者である確率がp3のとき、がん患者が検査の結果実際に陽性だと判定される確率を求めなさい。
Xを被検査者はガンであるという事象、Yを検査の結果が被検査者はガンであると示す事象として、それぞれ以下のように置き換えることができます。
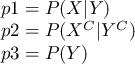
ただし、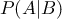 はBが起こったときにAが起こる確率(条件付き確率)、
はBが起こったときにAが起こる確率(条件付き確率)、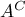 はAが起こらないという事象(補事象)を表します。
はAが起こらないという事象(補事象)を表します。
求めたい確率は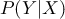 なので、ベイズの定理より
なので、ベイズの定理より
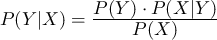
ここで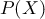 は検査結果が真陽性となる確率と偽陰性となる確率を足したものなので、
は検査結果が真陽性となる確率と偽陰性となる確率を足したものなので、
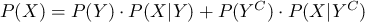
また、
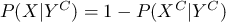
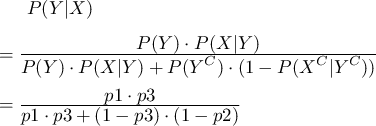
となります。
以上の結果に実際に値をあてはめてみます。
2008年のすい臓がん推定患者数は29584 1、同年の人口は127692000 2なので、p3=0.23168 * 10^-3。
また、簡単のためにp1, p2をひとまとめに誤検出の確率と仮定してp1=p2=qおくと、P(Y|X)が70%となるようなqは、q=0.99990となります。
このことから、99.99%の精度をもつ検出方法でも実際には30%も見逃してしまうということがわかります。
さらに、「400倍の精度で検査できる」という部分を誤検出の確率が400分の1になったという意味だと解釈して、
q'=1-(1-q)/400とおいてがん患者が検査の結果実際に陽性だと判定される確率を再度計算するとP(Y|X)=0.99892となります。
つまり30%見逃していたのが1%程度まで減ったということです。 これはすばらしい成果といえるのではないでしょうか。
最初は30%も見逃すとかどんなひどい検査だったんだ、などと思ってしまうかもしれませんが、上記の計算で実際はそれほど単純な話ではないことがわかると思います。

R Tutorial Part2 Chapter08 (Numerical Measures)
October 28, 2013 at 02:11 AM | categories: note, statistics, R |これはR Tutorial Part2 Chapter08 (Numerical Measures) のノートです。 slideはこちら 。
mean, median
- mean: 平均
- median: 中央値、中間値。データ数が偶数個の場合は前後の2つの数の平均。
> library(MASS) > mean(faithful$eruption) [1] 3.487783 > median(faithful$eruption) [1] 4
quartile, quantile, percentile
- first quartile, lower quartile: ソートされたデータの数を1:3に分ける位置の値。 第1四分位
- second quartile, median: 中間値
- third quartile, upper quartile: 第3四分位
- quantile: 変位値
- percentile: 百分位数
> quantile(faithful$eruption)
0% 25% 50% 75% 100%
1.60000 2.16275 4.00000 4.45425 5.10000
> x = sort(faithful$eruption)
> x[1+floor((length(x) - 1)/4)] + (x[1+ceiling((length(x) - 1)/4)] - x[1+floor((length(x) - 1)/4)]) * 3 / 4
[1] 2.16275
> quantile(faithful$eruption, c(.32, .57, .98))
32% 57% 98%
2.39524 4.13300 4.93300
max, min, range
> max(faithful$eruption) [1] 5.1 > min(faithful$eruption) [1] 1.6 > max(faithful$eruption) - min(faithful$eruption) [1] 3.5
interquartile range
- interquartile range: 四分位範囲, upper quartile - lower quartile
> IQR(faithful$eruption) [1] 2.2915 > x = quantile(faithful$eruption) > x[4] - x[2] 75% 2.2915
box plot
- boxplot: 箱ひげ図
> boxplot(faithful$eruption, horizontal=TRUE)
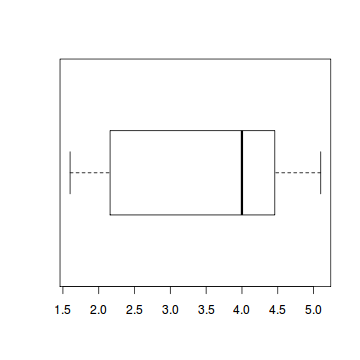
※ 箱のなかの線はmedian
variance, standard deviation
- variance: 分散。Rのvar関数は不偏分散
- standard deviation: 標準偏差
> var(faithful$eruption)
[1] 1.302728
> sd(faithful$eruption)
[1] 1.141371
> var2 <- function(x) { sum((x - mean(x)) ^ 2) / length(x) } # 普通の分散
> var2(faithful$eruption)
[1] 1.297939
covariance, correlation coefficient
- covariance: 共分散。2 組の対応するデータ間での、平均からの偏差の積の平均値。
- correlation coefficient: 相関係数。共分散をそれぞれのデータの標準偏差の積で割ったもの。
> cov(faithful$eruption, faithful$waiting) [1] 13.97781 > cor(faithful$eruption, faithful$waiting) [1] 0.9008112
correlation coefficientが1に近いほど正の相関があるといえる
e1071
Functions for latent class analysis, short time Fourier transform, fuzzy clustering, support vector machines, shortest path computation, bagged clustering, naive Bayes classifier
> install.packages('e1071')
http://cran.r-project.org/web/packages/e1071/index.html
central moment
- central moment: 中心積率。標本分散は2次のcentral moment
> library(e1071) > moment(faithful$eruption, order=3, center=TRUE) [1] -0.6149059
skewness, kurtosis
- skewness: 歪度。対象性の度合いの指標。一般に、skewness < 0 ならばmean < median でそのデータの分散はleft skewed という。skewness > 0 ならばmean > median でright skewed という。
- kurtosis: 尖度。分布の尖り具合の指標。kurtosis < 0 ならフラットな分布になりplatykurtic(緩尖な)という。kurtosis > 0ならとがった分布になりleptokurticという。正規分布の場合は0になりmesokurticという。
> skewness(faithful$eruption) [1] -0.4135498 > kurtosis(faithful$eruption) [1] -1.511605
misc
- この項は統計でよくつかう関数のまとめになってます
- 各関数の詳細はhelpを参照
About Me

|
mojavy |
Recent posts
95/5 Mbps とは
(August 30, 2015 at 04:22 PM)組み込み用プログラミング言語のパフォーマンス比較
(April 21, 2015 at 01:10 AM)最近読んだ本
(April 05, 2015 at 01:23 PM)Phabricatorを使ったワークフローについて
(March 02, 2015 at 08:55 PM)dnsimpleでダイナミックDNSをつかう
(December 23, 2014 at 08:02 PM)www2014のアドテク関連のResearch Trackメモ
(October 06, 2014 at 09:05 PM)flappymacs がMELPAに登録されました
(July 16, 2014 at 01:07 AM)EmacsでFlappy Birdっぽいもの書きました
(July 10, 2014 at 08:01 PM)
Recent Popular posts
Popular posts
Categories
- C (rss) (3)
- R (rss) (1)
- adtech (rss) (1)
- advent calendar (rss) (2)
- algorithms (rss) (2)
- android (rss) (2)
- aws (rss) (1)
- blog (rss) (2)
- blogofile (rss) (3)
- books (rss) (1)
- c++ (rss) (1)
- chef (rss) (4)
- common lisp (rss) (10)
- debian (rss) (2)
- dns (rss) (1)
- elasticsearch (rss) (1)
- elf (rss) (1)
- elisp (rss) (1)
- emacs (rss) (5)
- english (rss) (1)
- game (rss) (2)
- gearman (rss) (1)
- git (rss) (1)
- github (rss) (1)
- gitlab (rss) (1)
- golang (rss) (2)
- history (rss) (1)
- impress.js (rss) (1)
- internet (rss) (1)
- ios (rss) (3)
- jekyll (rss) (1)
- jenkins (rss) (1)
- linux (rss) (4)
- lisp (rss) (2)
- ltsv (rss) (1)
- lua (rss) (1)
- mac (rss) (3)
- mach-o (rss) (1)
- memo (rss) (2)
- mustache (rss) (1)
- note (rss) (1)
- objective-c (rss) (4)
- os (rss) (1)
- osx (rss) (2)
- others (rss) (1)
- paco (rss) (1)
- pdf (rss) (1)
- php (rss) (2)
- postfix (rss) (1)
- programming (rss) (12)
- project management (rss) (1)
- python (rss) (5)
- quicklinks (rss) (6)
- raspberry pi (rss) (2)
- redmine (rss) (1)
- reveal.js (rss) (1)
- ruby (rss) (10)
- sbcl (rss) (2)
- security (rss) (1)
- shell (rss) (2)
- smtp (rss) (1)
- solr (rss) (1)
- statistics (rss) (2)
- tips (rss) (10)
- tmux (rss) (3)
- toml (rss) (1)
- tools (rss) (1)
- twitter (rss) (1)
- ubuntu (rss) (1)
- unix (rss) (5)
- v8 (rss) (1)
- web (rss) (7)
- xcode (rss) (1)
- zeromq (rss) (2)
Archives
- August 2015 (1)
- April 2015 (2)
- March 2015 (1)
- December 2014 (1)
- October 2014 (1)
- July 2014 (3)
- March 2014 (6)
- February 2014 (4)
- November 2013 (3)
- October 2013 (4)
- September 2013 (2)
- July 2013 (2)
- June 2013 (2)
- May 2013 (1)
- April 2013 (6)
- March 2013 (3)
- February 2013 (8)
- January 2013 (5)
- December 2012 (1)
- November 2012 (6)
- October 2012 (7)
- August 2012 (1)
- July 2012 (9)
- June 2012 (1)
- April 2012 (1)
- December 2011 (2)
- November 2011 (2)