R Tutorial Part2 Chapter08 (Numerical Measures)
October 28, 2013 at 02:11 AM | categories: note, statistics, R |これはR Tutorial Part2 Chapter08 (Numerical Measures) のノートです。 slideはこちら 。
mean, median
- mean: 平均
- median: 中央値、中間値。データ数が偶数個の場合は前後の2つの数の平均。
> library(MASS) > mean(faithful$eruption) [1] 3.487783 > median(faithful$eruption) [1] 4
quartile, quantile, percentile
- first quartile, lower quartile: ソートされたデータの数を1:3に分ける位置の値。 第1四分位
- second quartile, median: 中間値
- third quartile, upper quartile: 第3四分位
- quantile: 変位値
- percentile: 百分位数
> quantile(faithful$eruption)
0% 25% 50% 75% 100%
1.60000 2.16275 4.00000 4.45425 5.10000
> x = sort(faithful$eruption)
> x[1+floor((length(x) - 1)/4)] + (x[1+ceiling((length(x) - 1)/4)] - x[1+floor((length(x) - 1)/4)]) * 3 / 4
[1] 2.16275
> quantile(faithful$eruption, c(.32, .57, .98))
32% 57% 98%
2.39524 4.13300 4.93300
max, min, range
> max(faithful$eruption) [1] 5.1 > min(faithful$eruption) [1] 1.6 > max(faithful$eruption) - min(faithful$eruption) [1] 3.5
interquartile range
- interquartile range: 四分位範囲, upper quartile - lower quartile
> IQR(faithful$eruption) [1] 2.2915 > x = quantile(faithful$eruption) > x[4] - x[2] 75% 2.2915
box plot
- boxplot: 箱ひげ図
> boxplot(faithful$eruption, horizontal=TRUE)
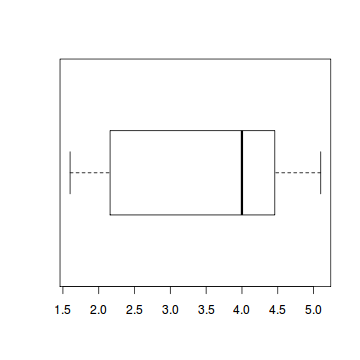
※ 箱のなかの線はmedian
variance, standard deviation
- variance: 分散。Rのvar関数は不偏分散
- standard deviation: 標準偏差
> var(faithful$eruption)
[1] 1.302728
> sd(faithful$eruption)
[1] 1.141371
> var2 <- function(x) { sum((x - mean(x)) ^ 2) / length(x) } # 普通の分散
> var2(faithful$eruption)
[1] 1.297939
covariance, correlation coefficient
- covariance: 共分散。2 組の対応するデータ間での、平均からの偏差の積の平均値。
- correlation coefficient: 相関係数。共分散をそれぞれのデータの標準偏差の積で割ったもの。
> cov(faithful$eruption, faithful$waiting) [1] 13.97781 > cor(faithful$eruption, faithful$waiting) [1] 0.9008112
correlation coefficientが1に近いほど正の相関があるといえる
e1071
Functions for latent class analysis, short time Fourier transform, fuzzy clustering, support vector machines, shortest path computation, bagged clustering, naive Bayes classifier
> install.packages('e1071')
http://cran.r-project.org/web/packages/e1071/index.html
central moment
- central moment: 中心積率。標本分散は2次のcentral moment
> library(e1071) > moment(faithful$eruption, order=3, center=TRUE) [1] -0.6149059
skewness, kurtosis
- skewness: 歪度。対象性の度合いの指標。一般に、skewness < 0 ならばmean < median でそのデータの分散はleft skewed という。skewness > 0 ならばmean > median でright skewed という。
- kurtosis: 尖度。分布の尖り具合の指標。kurtosis < 0 ならフラットな分布になりplatykurtic(緩尖な)という。kurtosis > 0ならとがった分布になりleptokurticという。正規分布の場合は0になりmesokurticという。
> skewness(faithful$eruption) [1] -0.4135498 > kurtosis(faithful$eruption) [1] -1.511605
misc
- この項は統計でよくつかう関数のまとめになってます
- 各関数の詳細はhelpを参照
reveal.js をつかってブログ記事からスライドを生成する
October 18, 2013 at 10:00 PM | categories: blog, reveal.js, blogofile |はじめに
これは以下のような人を対象にしたポストです
- スライドをmarkdownでつくりたい
- ブログはmarkdownでかいている
- ずぼらするためには努力を惜しまない
デモ
とりあえず以下のスライドをみてください。
reveal.jsとは
HTMLでかけるプレゼンツールです。詳細は以下等を参照してください。
static CMS
説明は省略します。このブログはblogofileでできていますが、jekyllやhakyllのようなものでもほぼ同等なことができます。
やり方
reveal.jsのmarkdown埋め込み機能をつかうだけです。reveal.jsのREADMEを読むとめんどうなように見えますが、 revealjs.mako のようにテンプレートを書くだけ。とはいえ多少のコーディングが必要です。
詳細は以下のソースをみてください。
code highlight
コードハイライトつかえます。
#include <stdio.h> // highlight test int main(int argc, char *argv[]) { printf("hello, world!\n"); return 0; }
fragment
fragmentもつかえます。
... to step through ...
any type- of view
- fragments
長所
- ブログ書くついてでにスライドもできる
- スライドの共有が簡単
- パワポ不要
- さりげなくギークっぽさがアピールできる
短所
- ブログとスライドのそれぞれの完成度を両立した記事にまとめるのは難しい
- 多少はhtmlを書く必要があるときもある
まとめ
- blogofileにreveal.jsを組み込んだ話を紹介しました
- reveal.jsかっこいいです
オーバーフローしにくい組み合わせの数の計算方法
October 17, 2013 at 09:13 PM | categories: algorithms, programming |Cで組み合わせの数を計算するときに定義通り計算するとすぐにオーバーフローしてしまう。
例えば以下のような実装だと、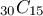 程度でも結果がおかしくなってしまう。
程度でも結果がおかしくなってしまう。
#include <iostream> using namespace std; uint64_t fac(uint64_t n) { if (n > 1) return n * fac(n-1); else return 1; } uint64_t combinations(uint64_t n, uint64_t k) { return fac(n) / (fac(k) * fac(n-k)); } int main(int argc, char *argv[]) { cout << combinations(5, 3) << endl; // => 10 cout << combinations(10, 5) << endl; // => 252 cout << combinations(20, 10) << endl; // => 184756 cout << combinations(30, 15) << endl; // => 0 !? return 0; }
とりあえず素因数分解してやれば解決するのでいままでそうしてたのだけど、もっとかっこいい方法がないものかと思って探してみたらKnuth先生の本で以下のようなアルゴリズムが紹介されているらしい。1 これはかっこいい。
uint64_t combinations2(uint64_t n, uint64_t k) { uint64_t r = 1; for (uint64_t d = 1; d <= k; ++d) { r *= n--; r /= d; } return r; } int main(int argc, char *argv[]) { cout << combinations2(30, 15) << endl; // => 155117520 cout << combinations2(60, 30) << endl; // => 118264581564861424 cout << combinations2(64, 32) << endl; // これはオーバーフローする return 0; }
結果の値が範囲内ならオーバーフローしないのか、というとそういうわけではないけどナイーブな実装に比べるとずっと計算できる範囲が広いので、値のレンジがあらかじめわかっているのであればこれで十分ですね。
mustache基礎文法最速マスター
October 01, 2013 at 12:08 AM | categories: ruby, mustache |![]()
mustacheはシンプルなテンプレートエンジンなので本家の英語マニュアル mustache(5) を見ても大したことはないですが、日本語情報の需要もそれなりにあると思うのでまとめておきます。
以下の内容はrubygemのmustache-0.99.4で確認しています。
他の言語の場合は適宜置きかえてください。
目次
変数の展開
{{name}}のように2つのブレースで囲ったタグは、nameという名前のキーの値でおきかえられます。
対応するキーが見つからなかった場合はデフォルトでは空文字になります。
Mustache.render("Hello, {{world}}!", world: "mustache") # => "Hello, mustache!" Mustache.render("{{no_such_key}}") # => ""
変数のエスケープ
デフォルトではHTMLエスケープが有効になります。アンエスケープされたHTMLが使いたい場合は{{{name}}}のように3つのブレースで囲います。
Mustache.render("{{html}}", html: "<b>GitHub</b>") # => "<b>GitHub</b>" Mustache.render("{{{html}}}", html: "<b>GitHub</b>") # => "<b>GitHub</b>"
条件分岐
{{#name}} ... {{/name}}のように、2つのタグに#と/をそれぞれつけたタグで囲われたブロックはセクションといいます。
セクションのキーに対応する値にbool値を渡せばif文のような使い方ができます。
#のかわりに^をつかうと真偽を反転できます。
template = <<DOC {{#condition}} It is true. {{/condition}} {{^condition}} No not true. {{/condition}} DOC Mustache.render(template, condition: true) # => "It is true.\n" Mustache.render(template, condition: false) # => "No not true.\n"
ループ
セクションのキーに対応する値に配列を渡した場合は、それぞれの要素を引数として中のブロックが繰り返し評価されます。
template = <<DOC {{#animals}} {{name}} {{/animals}} DOC data = {animals: [{name: "cat"}, {name: "dog"}, {name: "pig"}]} Mustache.render(template, data) # => "cat\ndog\npig\n"
無名関数 (Lambda)
セクションのキーに対応する値に呼び出し可能なオブジェクトを渡した場合は、そのブロック内のテキストを引数として実行され、その返り値が結果として出力されます。
template = <<DOC {{#proc}} mojavy is bad {{/proc}} DOC Mustache.render(template, proc: ->text{text.gsub(/bad/, 'nice')}) # => "mojavy is nice\n"
コメント
!をつけるとコメントになります
Mustache.render("Comment here: {{! ignore me }}") # => "Comment here: "
まとめ
mustacheの基本的な機能について簡単なサンプルコードとともに解説しました。 ここではrubyのmustacheを使用しましたが、他の言語でも同様の機能が使えます。 一部の機能については省略しているので、より詳細な情報については本家ドキュメントを参照してください。
About Me

|
mojavy |
Recent posts
95/5 Mbps とは
(August 30, 2015 at 04:22 PM)組み込み用プログラミング言語のパフォーマンス比較
(April 21, 2015 at 01:10 AM)最近読んだ本
(April 05, 2015 at 01:23 PM)Phabricatorを使ったワークフローについて
(March 02, 2015 at 08:55 PM)dnsimpleでダイナミックDNSをつかう
(December 23, 2014 at 08:02 PM)www2014のアドテク関連のResearch Trackメモ
(October 06, 2014 at 09:05 PM)flappymacs がMELPAに登録されました
(July 16, 2014 at 01:07 AM)EmacsでFlappy Birdっぽいもの書きました
(July 10, 2014 at 08:01 PM)
Recent Popular posts
Popular posts
Categories
- C (rss) (3)
- R (rss) (1)
- adtech (rss) (1)
- advent calendar (rss) (2)
- algorithms (rss) (2)
- android (rss) (2)
- aws (rss) (1)
- blog (rss) (2)
- blogofile (rss) (3)
- books (rss) (1)
- c++ (rss) (1)
- chef (rss) (4)
- common lisp (rss) (10)
- debian (rss) (2)
- dns (rss) (1)
- elasticsearch (rss) (1)
- elf (rss) (1)
- elisp (rss) (1)
- emacs (rss) (5)
- english (rss) (1)
- game (rss) (2)
- gearman (rss) (1)
- git (rss) (1)
- github (rss) (1)
- gitlab (rss) (1)
- golang (rss) (2)
- history (rss) (1)
- impress.js (rss) (1)
- internet (rss) (1)
- ios (rss) (3)
- jekyll (rss) (1)
- jenkins (rss) (1)
- linux (rss) (4)
- lisp (rss) (2)
- ltsv (rss) (1)
- lua (rss) (1)
- mac (rss) (3)
- mach-o (rss) (1)
- memo (rss) (2)
- mustache (rss) (1)
- note (rss) (1)
- objective-c (rss) (4)
- os (rss) (1)
- osx (rss) (2)
- others (rss) (1)
- paco (rss) (1)
- pdf (rss) (1)
- php (rss) (2)
- postfix (rss) (1)
- programming (rss) (12)
- project management (rss) (1)
- python (rss) (5)
- quicklinks (rss) (6)
- raspberry pi (rss) (2)
- redmine (rss) (1)
- reveal.js (rss) (1)
- ruby (rss) (10)
- sbcl (rss) (2)
- security (rss) (1)
- shell (rss) (2)
- smtp (rss) (1)
- solr (rss) (1)
- statistics (rss) (2)
- tips (rss) (10)
- tmux (rss) (3)
- toml (rss) (1)
- tools (rss) (1)
- twitter (rss) (1)
- ubuntu (rss) (1)
- unix (rss) (5)
- v8 (rss) (1)
- web (rss) (7)
- xcode (rss) (1)
- zeromq (rss) (2)
Archives
- August 2015 (1)
- April 2015 (2)
- March 2015 (1)
- December 2014 (1)
- October 2014 (1)
- July 2014 (3)
- March 2014 (6)
- February 2014 (4)
- November 2013 (3)
- October 2013 (4)
- September 2013 (2)
- July 2013 (2)
- June 2013 (2)
- May 2013 (1)
- April 2013 (6)
- March 2013 (3)
- February 2013 (8)
- January 2013 (5)
- December 2012 (1)
- November 2012 (6)
- October 2012 (7)
- August 2012 (1)
- July 2012 (9)
- June 2012 (1)
- April 2012 (1)
- December 2011 (2)
- November 2011 (2)