組み込み用プログラミング言語のパフォーマンス比較
April 21, 2015 at 01:10 AM | categories: v8, lua, lisp, programming, ruby |組み込み用のプログラミング言語といえばLuaがよく使われるけど、最近はmrubyやsquirrelもあって選択肢が広がってきた感があるのでどういう特徴があるのかを知るためにベンチマークをやってみた。
今回対象にしたのは以下。
- Lua - v5.1
- LuaJIT - v2.0.2
- squirrel - v3.0.7
- V8 - v3.30
- mruby - v1.1.0
- ecl (Embeddable Common-Lisp) - v15.3.7
ここでのベンチマークは言語自体のスピードの比較ではなく、どちらかというと組み込む際に必要なオーバーヘッドやホスト言語側での処理にかかる部分に重点を置いた。
ベンチマークの処理では、関数呼出し比較用のecho関数と、テーブル操作比較用のinvert関数を組み込み言語側に実装して、それを繰り返し呼び出すようにした。
また、なるべく公平になるように、組み込み言語側の関数は初期化時にグローバルスコープ(組み込み言語側のグローバルスコープ)に登録しておき、すべて同じインターフェースから呼ぶようにした。
使用したコードは以下。そのうち別の言語とか追加するかもしれない。
https://github.com/taksatou/embench
結果
echo 100000 回実行
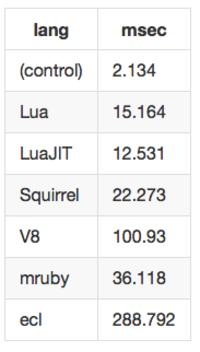
invert 100000 回実行
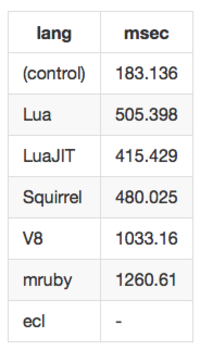
https://gist.github.com/taksatou/8de85bbfe79548864cf5#file-result-md
備考
- control は同等の処理をホスト言語側で実装したもの
- LuaJITは
LD_PRELOADで切り替えた - eclはechoが遅くてやるきを失ったのでinvertのほうは省略
所感
- Luaがパフォーマンスと組み込みやすさの点でやはり一番使いやすい。LuaJITをつかうとさらに数割速くなる。
- squirrelは言語機能的にはluaのスーパーセットという感じで、パフォーマンスもluaと同じ程度。ただしドキュメントはあまりない。
- V8はマルチスレッド環境や大規模なものには向いてるかもしれない。組み込みはちょっとめんどくさい。
- mrubyはechoだと意外と健闘しているがテーブル操作は速くない。組み込みはLuaと同じくらい簡単。
- eclにはもうちょっとがんばってほしい。組み込み方法に問題があるのかもしれない。
Phabricatorを使ったワークフローについて
March 02, 2015 at 08:55 PM | categories: tools, programming, project management |![]()
最近 Phabricator を使ったワークフローを試しています。FacebookやDropboxをはじめとして海外では割と良く使われているようですが、あまり国内には情報がないようなのでまとめておきます。
Phabricatorでできること
Phabricatorはコードレビューがメイン機能のようですが、それに留まらずソフトウェアの開発で必要なものがワンストップでまとまったプロジェクト管理ツールになっています。
メニューのネーミングが独特でとっつきづらいですが、主に以下のような機能があります。
Differential: pre push型のコードレビューAudit: post push型のコードレビューManiphest: タスクとバグの管理Diffusion: リポジトリの管理Harald: commitやタスクの更新イベントにフックして起動する処理の管理Phriction: Wiki
また、arcanist というコマンドラインから操作するためのツールも別途提供されており、開発のワークフローも含めた統合が意図されているようです。
セットアップ
docker環境があるなら docker run yesnault/docker-phabricator ですぐ試せます。
https://registry.hub.docker.com/u/yesnault/docker-phabricator/
ただし、上記dockerfileから構築したコンテナはデフォルトだとメールは外部に送信できない設定になっています。admin以外のユーザ登録ではメールアドレス認証が必要なので、docker exec -it <container_id> bash でコンテナに入ってメール設定を適宜修正して下さい。
dockerを使わずに普通にインストールする場合は https://secure.phabricator.com/book/phabricator/article/installation_guide/ を参照してください。
起動直後は色々設定を聞かれますが、特につまるようなところはないので省略します。
Phabricatorでのコードレビュー
pre-push型のコードレビュー (Differential)
pre-push型のコードレビューは、フロー的にはGithubでのPull Requestに似ていますが、レビュー対象のcommitをpushするのではなく、パッチを送る点が異なります。Phabricatorでは以下のようなフローで作業することになります。
- コードを修正した人(author)は、レビュワー(reviewer)を指定して変更内容をDifferentialに登録する
- reviewerは通知を受けてレビューをする
- reviwerがacceptしたら、authorはupstreamにpushする
diffをPhabricatorにコピペして登録することもできますが、基本的にはarcanist経由で作業することになります。
PhabricatorのUser GuideにはDifferentialの良さ が長々と書かれてますが、実際のところ、長所として挙げられている項目はどれもPull Requestベースでも達成できます。 ただ、Defferentialとarcanistを使えば簡単にレビュー依頼が投げられるので、開発者が自発的に適切な粒度でレビュー依頼する助けにはなりそうです。
post-push型のコードレビュー (Audit)
Differentialではレビューが完了するまでpushを待つ必要がありますが、Auditはレビューを待たずにpushしてその後にレビューを実施するための機能です。
例えば、急いでリリースする必要がある場合でも、Auditを用いてあとからレビューすることができます。このときに問題が見つかればProblem Commitsというフラグをたてておいてタスクに積む、というような使い方になるようです。
Haraldという機能を使えば特定の条件に合致するcommit(例えば変更が大きい、Differentialでレビューされていない、等)があった場合は自動的にAuditを生成させることもできます。
Auditをpull requestのように使うこともできますが、推奨はされていないようです。
所感
もし開発管理のためにredmineやjiraをつかっているのであればPhabricatorは良い代替になりそうです。開発者向けに特化してる分、プロジェクトのタスクやバグ管理がソースコードとうまく統合されていて、ダッシュボードも柔軟にカスタマイズできます。githubのissueに不満を感じている人もPhabricatorのワークフローは試してみる価値があると思います。
レビューツール単体としてみると、(Differentialをつかうなら)開発者にarcanistの導入をしてもらう必要がある分、Pull Requestの手軽さに比べるとやや煩雑に感じました。既にPull Requestベースの開発が定着していて、単によりよいレビューツールを探しているのであればGerrit 等のほうが導入しやすいかもしれません。
その他
- https://showoff.phab.io/ でデモPhabricatorが使えるので一通り試せます。
- デフォルトではかなりの頻度でリポジトリに対してポーリングしに行きます。負荷をかけ過ぎないように注意が必要です。
- Phabricator自体もそれなりの性能のマシンが必要です。環境によってはworker数を減らしたりmysqlのメモリサイズを調整しておく必要があります。
参考
C++のdreaded diamondについて
July 09, 2014 at 09:56 PM | categories: programming, c++ |以下のようなダイアモンド継承をしたときに発生する問題のことをdreaded diamondと呼ぶらしい。
Base
/ \
D1 D2
\ /
D3
例えば以下のようなクラスではアップキャストをするときやBaseクラスのメンバにアクセスするときに曖昧性が生じる。
class Base { public: int data; virtual ~Base() {} }; class D1 : public Base { public: virtual ~D1() {} }; class D2 : public Base { public: virtual ~D2() {} }; class D3 : public D1, public D2 { public: virtual ~D3() {} };
以下のようなコードをコンパイルしようとしてもエラーになる。
void f1() { D3 d3; Base &base = d3; d3.data = 123; }
ambiguous conversion from derived class 'D3' to base class 'Base':
class D3 -> class D1 -> class Base
class D3 -> class D2 -> class Base
Base &base = d3;
^~
non-static member 'data' found in multiple base-class subobjects of type 'Base':
class D3 -> class D1 -> class Base
class D3 -> class D2 -> class Base
d3.data = 123;
^
これを回避するためには明示的に中継するクラスを指定してやる必要がある。
void f2() { D3 d3; Base &base = dynamic_cast<D1&>(d3); d3.D1::data = 123; d3.D2::data = 456; cout << d3.D1::data << ',' << d3.D2::data << endl; // => 123,456 }
でも普通は継承元にそれぞれの別々の親を持つのではなく、共通の1つだけを持っていてほしい。 それを解決するには仮想継承を使う。
class D1 : public virtual Base { /* 省略 */ }; class D2 : public virtual Base { /* 省略 */ }; class D3 : public D1, public D2 { /* 省略 */ };
このようにすればBaseクラスのインスタンスは1つだけになって曖昧性が解消される。
void f3() { D3 d3; Base &base = d3; d3.data = 123; cout << d3.D1::data << ',' << d3.D2::data << endl; // => 123,123 }
pthreadの取り消しポイント(cancellation point)についてのメモ
March 18, 2014 at 09:41 PM | categories: unix, programming |cancellation pointsとは、スレッドのキャンセル種別がdeferredのときに、そこに到達したときにはじめて実際にそのスレッドのキャンセル要求が処理されるような関数のこと。
POSIX.1では、基本的にはブロックするような関数がcancellation pointsであることが要求されている。
参考
malloc+memsetとcallocの違いについて
March 05, 2014 at 09:25 PM | categories: os, programming |mallocとcallocの違いは、表面的には引数の数とcallocは確保した領域を0で初期化するという点くらいですが、以下のコードを大きなnで実行すると、今時のOSだとmalloc + memsetのほうが大幅に遅くなる可能性があります。
void *p = malloc(n * sizeof(type)); memset(p, 0, n * sizeof(type));
void *p = calloc(n, sizeof(type));
カーネルはセキュリティ上の理由からメモリを0で初期化してからユーザプロセスに渡します。
しかし、仮想メモリをサポートしたシステムでは、実際にそのメモリに書き込みが発生するまでカーネルはread onlyな領域を複数プロセスで共有させることができるため、既に初期化してあるページであればこの処理を省略できる場合があります。
brkで拡張した領域は0で初期化されているので、callocは新規確保した領域は初期化を省略することができ、結果的にcallocを実行したタイミングでは初期化が実際にはほとんど発生しない、ということがありえます。
一方memsetの場合は実際にメモリへの書込みが発生する上、ページの共有もできなくなるためswapする可能性もあります。
ちなみに、(カーネルではなく)calloc自身が0初期化する処理と、memsetの処理は微妙に違います。
なぜなら、memsetは対象の領域がアラインされているかどうかについての情報なしに処理する必要があるので、境界部分は1byteずつやるしかありません。
じゃあmemsetのほうが遅いのかというと、コンパイラによってはアラインされていることを推測できる場合もあったり、callocはライブラリ関数なので移植性のために最適化しにくかったりするので、結局のところ微妙です。
参考: http://stackoverflow.com/questions/2688466/why-mallocmemset-is-slower-than-calloc
About Me

|
mojavy |
Recent posts
95/5 Mbps とは
(August 30, 2015 at 04:22 PM)組み込み用プログラミング言語のパフォーマンス比較
(April 21, 2015 at 01:10 AM)最近読んだ本
(April 05, 2015 at 01:23 PM)Phabricatorを使ったワークフローについて
(March 02, 2015 at 08:55 PM)dnsimpleでダイナミックDNSをつかう
(December 23, 2014 at 08:02 PM)www2014のアドテク関連のResearch Trackメモ
(October 06, 2014 at 09:05 PM)flappymacs がMELPAに登録されました
(July 16, 2014 at 01:07 AM)EmacsでFlappy Birdっぽいもの書きました
(July 10, 2014 at 08:01 PM)
Recent Popular posts
Popular posts
Categories
- C (rss) (3)
- R (rss) (1)
- adtech (rss) (1)
- advent calendar (rss) (2)
- algorithms (rss) (2)
- android (rss) (2)
- aws (rss) (1)
- blog (rss) (2)
- blogofile (rss) (3)
- books (rss) (1)
- c++ (rss) (1)
- chef (rss) (4)
- common lisp (rss) (10)
- debian (rss) (2)
- dns (rss) (1)
- elasticsearch (rss) (1)
- elf (rss) (1)
- elisp (rss) (1)
- emacs (rss) (5)
- english (rss) (1)
- game (rss) (2)
- gearman (rss) (1)
- git (rss) (1)
- github (rss) (1)
- gitlab (rss) (1)
- golang (rss) (2)
- history (rss) (1)
- impress.js (rss) (1)
- internet (rss) (1)
- ios (rss) (3)
- jekyll (rss) (1)
- jenkins (rss) (1)
- linux (rss) (4)
- lisp (rss) (2)
- ltsv (rss) (1)
- lua (rss) (1)
- mac (rss) (3)
- mach-o (rss) (1)
- memo (rss) (2)
- mustache (rss) (1)
- note (rss) (1)
- objective-c (rss) (4)
- os (rss) (1)
- osx (rss) (2)
- others (rss) (1)
- paco (rss) (1)
- pdf (rss) (1)
- php (rss) (2)
- postfix (rss) (1)
- programming (rss) (12)
- project management (rss) (1)
- python (rss) (5)
- quicklinks (rss) (6)
- raspberry pi (rss) (2)
- redmine (rss) (1)
- reveal.js (rss) (1)
- ruby (rss) (10)
- sbcl (rss) (2)
- security (rss) (1)
- shell (rss) (2)
- smtp (rss) (1)
- solr (rss) (1)
- statistics (rss) (2)
- tips (rss) (10)
- tmux (rss) (3)
- toml (rss) (1)
- tools (rss) (1)
- twitter (rss) (1)
- ubuntu (rss) (1)
- unix (rss) (5)
- v8 (rss) (1)
- web (rss) (7)
- xcode (rss) (1)
- zeromq (rss) (2)
Archives
- August 2015 (1)
- April 2015 (2)
- March 2015 (1)
- December 2014 (1)
- October 2014 (1)
- July 2014 (3)
- March 2014 (6)
- February 2014 (4)
- November 2013 (3)
- October 2013 (4)
- September 2013 (2)
- July 2013 (2)
- June 2013 (2)
- May 2013 (1)
- April 2013 (6)
- March 2013 (3)
- February 2013 (8)
- January 2013 (5)
- December 2012 (1)
- November 2012 (6)
- October 2012 (7)
- August 2012 (1)
- July 2012 (9)
- June 2012 (1)
- April 2012 (1)
- December 2011 (2)
- November 2011 (2)